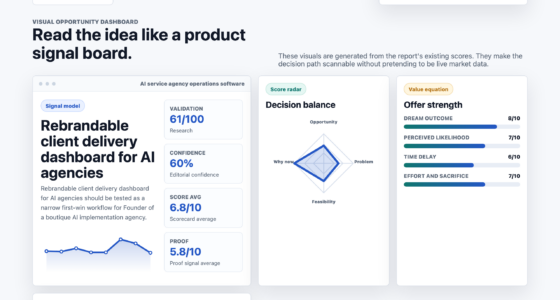
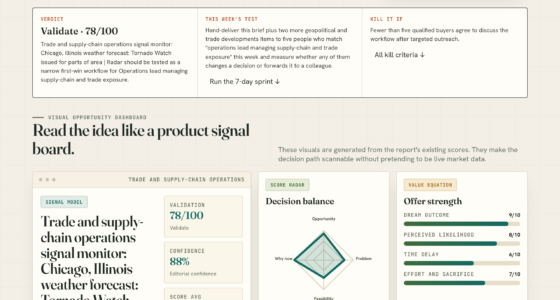
📊 Full opportunity report: Mac vs GPU Tower for Local LLMs: The Heat-and-Noise Tradeoff on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
This article compares Mac Studio with Apple Silicon and GPU towers for running local large language models, focusing on heat, noise, and performance. The choice hinges on model size, throughput needs, and thermal management.
Apple Silicon machines like the Mac Studio offer near-silent operation and low power consumption, contrasting sharply with GPU towers that generate significant heat and noise. This comparison highlights fundamental tradeoffs affecting AI practitioners choosing between these architectures for local large language model inference.
GPU towers equipped with high-end NVIDIA RTX cards deliver substantially higher memory bandwidth—up to 1,792 GB/s—enabling faster inference on models fitting within VRAM, often 32GB or less. They can scale with multiple GPUs, supporting CUDA and fine-tuning workflows, but at the cost of high power consumption, often exceeding 575W per GPU, and significant heat output requiring complex thermal management. In contrast, Apple Silicon Macs like the M3 Ultra integrate up to 512GB of unified memory, allowing them to run larger models—70B+—that do not fit in GPU VRAM, albeit at slower speeds. These Macs operate quietly and consume minimal power, making them ideal for always-on, noise-sensitive environments, though they lack multi-GPU scaling and native CUDA support. The core difference lies in the architecture: GPUs prioritize bandwidth and throughput, while Apple Silicon emphasizes capacity and energy efficiency.Mac vs GPU tower
for local LLMs.
What if you sidestep the heat entirely with a different kind of machine? A tower is a high-bandwidth furnace you spend five levers quieting. Apple Silicon is near-silent by design — but asks for different tradeoffs. Match your priority in Part 2.
Put the loud, hot machine where its noise doesn’t matter, and the quiet one where you do. SSH into the tower when you need raw power; let the Mac handle everything else, silently.
Impact of Heat and Noise on AI Workstation Choices
Understanding these tradeoffs is crucial for AI developers and organizations. GPU towers maximize raw inference speed and model fine-tuning capabilities but require extensive thermal management and generate disruptive noise. Apple Silicon offers a silent, power-efficient alternative for large models that fit within its unified memory, transforming the setup for continuous, low-noise operation. The decision influences hardware investments, workflow design, and operational costs, especially for users prioritizing quiet environments or energy savings.

VIPERA NVIDIA GeForce RTX 4090 Founders Edition Graphic Card
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Fundamental Architectural Differences Drive Tradeoffs
The debate between Mac Silicon and GPU towers hinges on core architectural distinctions. GPU towers leverage high bandwidth to accelerate inference on smaller models, with the ability to scale via multiple GPUs and support CUDA ecosystems. These setups are power-hungry, produce significant heat, and demand complex thermal management. Conversely, Apple Silicon's unified memory architecture allows for larger models to be loaded into a single device, sacrificing some speed for capacity and energy efficiency. This shift reflects a broader trend toward integrating AI workloads into more energy-conscious, quieter hardware, but with limitations on multi-GPU scaling and native CUDA support.
"The heat-and-noise dimension is one of the sharpest differences between a GPU tower and an Apple Silicon machine, fundamentally shaping their suitability for local AI."
— Thorsten Meyer

GEEKRIA Chassis Stand, Compatible with Apple Mac Studio for M1/M2/M4 Max, M1/M2/M3 Ultra. Acrylic Computer Case Holder, Mount, Desktop Accessories, Optimized Heat Dissipation (Frosted)
This chassis stand can prevent spills and damage to the device, and can also prevent dust, so that...
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Unresolved Questions About Long-Term Scalability
It remains unclear how future GPU architectures might reduce heat and noise or how Apple Silicon's performance will evolve with new generations. Additionally, the practical limits of unified memory for even larger models and the development of native CUDA support on Apple Silicon are still uncertain.

ASRock Radeon AI PRO R9700 Creator 32GB Professional Graphics Card, 2920 MHz Boost Clock, GDDR6, AMD RDNA 4, AI-Accelerators, DisplayPort 2.1a, PCIe 5.0, Blower Cooler
Professional AI & Creator Workstation: AMD Radeon AI PRO R9700 GPU with 32GB GDDR6 is engineered for AI...
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Future Developments in Hardware for Local AI
Next steps include observing how GPU manufacturers improve thermal management and how Apple advances its unified memory and performance capabilities. Users will also watch for software ecosystem developments, such as native CUDA support on Apple Silicon, which could shift the balance in hardware choices for local large language model inference.
quiet thermal management PC for AI workloads
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Can Apple Silicon machines run large models faster?
They can load larger models that don't fit in GPU VRAM, but inference speed is generally slower compared to GPU towers optimized for bandwidth.
Is noise a significant factor when choosing hardware for AI?
Yes, GPU towers produce considerable heat and noise, requiring complex thermal management, whereas Apple Silicon operates quietly and with minimal heat output.
Will future GPU or Apple Silicon updates change this comparison?
Potentially. GPU improvements may reduce heat and noise, while Apple Silicon might increase capacity and speed, but current differences remain significant.
Which hardware is better for continuous, low-noise operation?
Apple Silicon Macs are designed for silent, power-efficient operation, making them ideal for always-on environments.
Can I upgrade a Mac Studio's hardware later?
No, Apple Silicon devices are fixed at purchase; upgrading requires replacing the entire machine.
Source: ThorstenMeyerAI.com